



The Weekly Weird #41
AI kills online language research, these are not the 'shrooms you're looking for, Australia poops on speech, Hong Kong poops on academic freedom, Telegram spreads 'em


Greetings and salutations, fellow Weirders (Weirdos?), and welcome back to your weekly instalment of the latest dystopian doings!
This week’s up-fronts are:
CJ Hopkins goes on (re)trial on Monday 30 September at 10:30 am in Room 145a at Berlin’s Kammergericht. He and his attorney Friedemann Däblitz join me to discuss the case in the next episode of the podcast, out this Sunday.
Hatun Tash, an ex-Muslim Christian, won a compensation case against London’s Metropolitan Police after they arrested her for having her copy of the Quran stolen at Speaker’s Corner (and wearing a Charlie Hebdo t-shirt). It’s a twisty tale, and she’ll be joining me on an upcoming episode to talk about it.
Walter Russell Mead, in an op-ed for The Wall Street Journal titled U.S. Shrugs as World War III Approaches, dropped the following nugget: “World War III is becoming more likely in the near term, and the U.S. is too weak either to prevent it or, should war come, to be confident of victory. A more devastating indictment of a failed generation of national leadership could scarcely be penned.”
Good times!
Let’s get cracking…
AI Kills Online Language Research
Wordfreq, a data project studying online word usage, will no longer be updated because “Generative AI has polluted the data”, according to an update on their GitHub page.
Robyn Speer, the developer running Wordfreq, described her reasons for sunsetting the project in stark terms:
I don't think anyone has reliable information about post-2021 language usage by humans.
The open Web (via OSCAR) was one of wordfreq's data sources. Now the Web at large is full of slop generated by large language models, written by no one to communicate nothing. Including this slop in the data skews the word frequencies.
Sure, there was spam in the wordfreq data sources, but it was manageable and often identifiable. Large language models generate text that masquerades as real language with intention behind it, even though there is none, and their output crops up everywhere.
As one example, Philip Shapira reports that ChatGPT (OpenAI's popular brand of generative language model circa 2024) is obsessed with the word "delve" in a way that people never have been, and caused its overall frequency to increase by an order of magnitude.
Here is the graph used by Shapira on his blog to demonstrate the exponential increase in the use of the word “delve” since the advent of Chat-GPT.
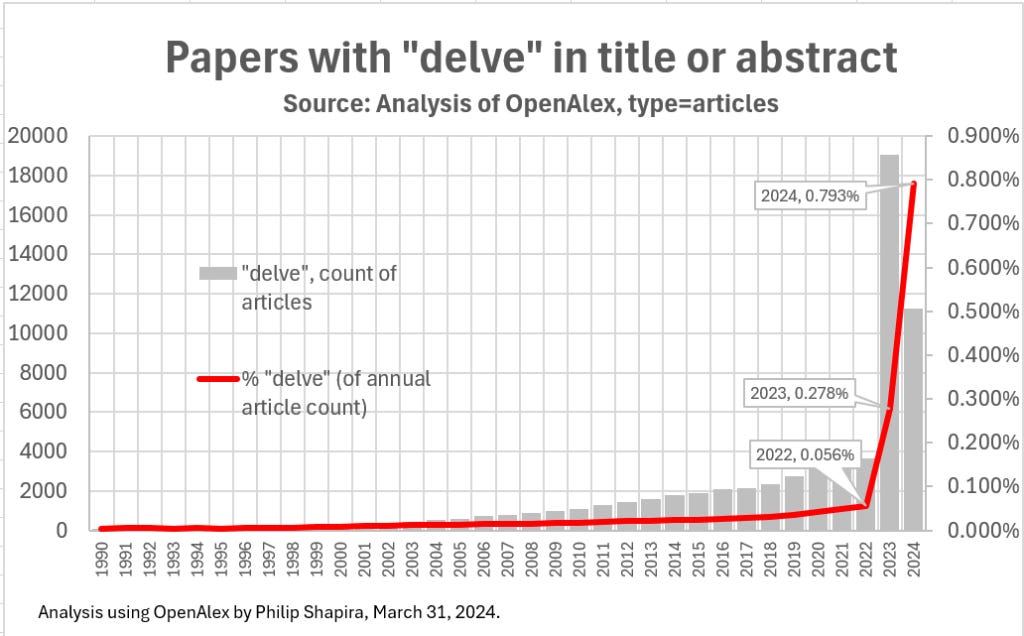
The explosion in the use of this otherwise seldom-utilised word is also specifically timed to the widespread launch of Chat-GPT in a globally-accessible way:
Some 30,276 (or 46%) of all the 66,158 papers that mention “delve” posted on OpenAlex between 1990 and March 31, 2024 came out in the 15-month period from January 2023 to the end of March 2024.
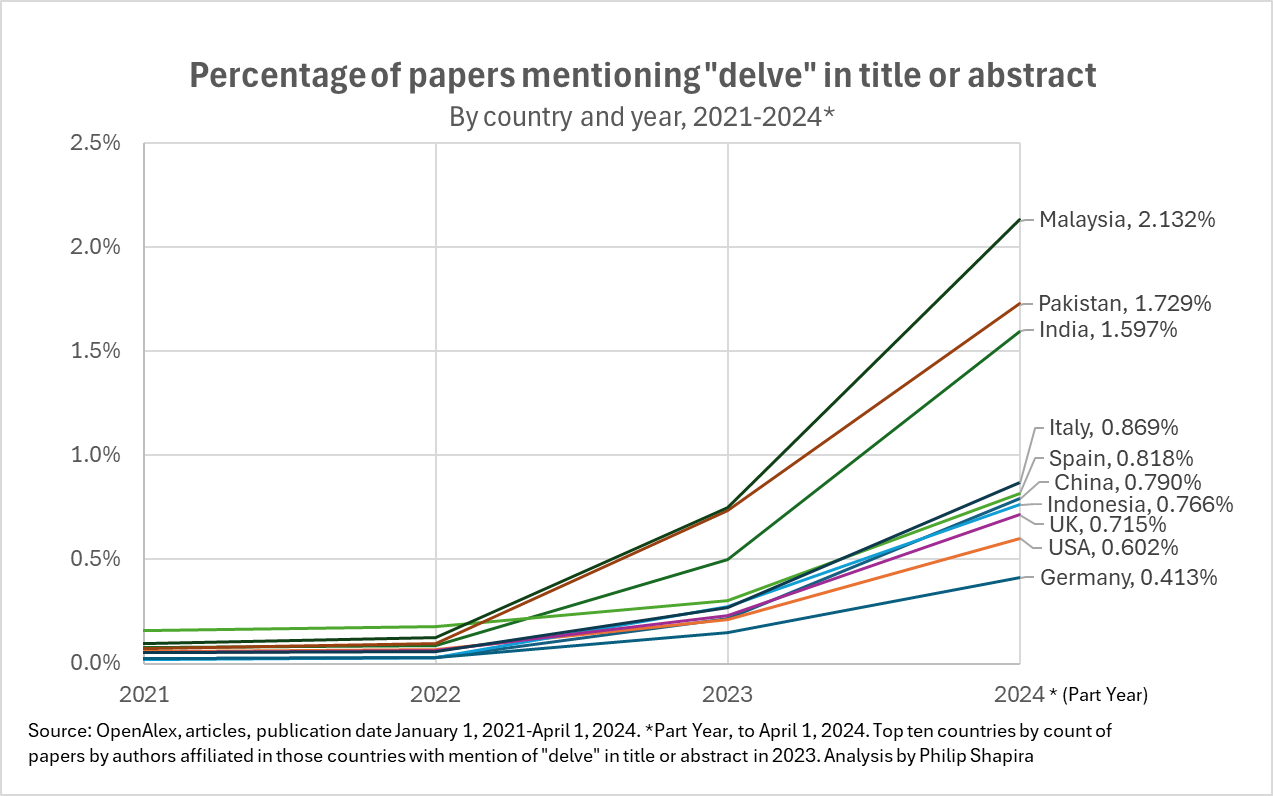
The increase in usage of that word in particular, when cross-referenced against the location of the authors, gives an interesting picture of where Chat-GPT uptake may be the highest, and by extension, where it is most likely to be used for writing rather than merely augmenting text.
In her description of how the landscape has changed, and why that affected her willingness to continue with the Wordfreq project, Speer adds that sources of word use data like X (which she calls “an oligarch's plaything, a spam-infested right-wing cesspool”) and Reddit have become inaccessible, unusable, or too expensive:
Even if X made its raw data feed available (which it doesn't), there would be no valuable information to be found there.
Reddit also stopped providing public data archives, and now they sell their archives at a price that only OpenAI will pay.
Her special burning ire is reserved for generative AI and the companies that have made it the only show in Tech Town:
The field I know as "natural language processing" is hard to find these days. It's all being devoured by generative AI. Other techniques still exist but generative AI sucks up all the air in the room and gets all the money. It's rare to see NLP research that doesn't have a dependency on closed data controlled by OpenAI and Google, two companies that I already despise.
wordfreq was built by collecting a whole lot of text in a lot of languages. That used to be a pretty reasonable thing to do, and not the kind of thing someone would be likely to object to. Now, the text-slurping tools are mostly used for training generative AI, and people are quite rightly on the defensive. If someone is collecting all the text from your books, articles, Web site, or public posts, it's very likely because they are creating a plagiarism machine that will claim your words as its own.
So I don't want to work on anything that could be confused with generative AI, or that could benefit generative AI.
OpenAI and Google can collect their own damn data, and I hope they have to pay a very high price for it. They made this mess themselves.
The upbeat takeaway, from Speer, is that it’s still worthwhile preserving a snapshot of how humans used language on the internet before LLMs took over (emphasis in the original):
You could see this freezing of wordfreq data as a good thing. Many people have found wordfreq useful, and the latest version isn't going away. The conclusion that I'm documenting here is that updating it would make it worse, so instead, I'm not updating it. It'll become outdated over time, but it won't get actively worse. That's a pretty okay fate for something on the Internet!
So there you have it. Sunset for “natural language”, sunrise for “slop”, at least in cyberspace.
These Are Not The ‘Shrooms You’re Looking For
Generative AI isn’t just crowding out natural human language online, it’s potentially endangering humans looking to interact with nature.
404 Media reports that “Google is serving AI-generated images of mushrooms when users search for some species, a risky and potentially fatal error for foragers who are trying to figure out what mushrooms are safe to eat.”
In other words, search results are showing AI-generated images of a foodstuff that can be either delicious or deadly depending on slight variations in colour, size, cap ridging, stem thickness and an assortment of other minute details. What could go wrong?
MycoMutant, a mushroom maven on Reddit, shared the horror:
Searching Coprinus comatus the first image I see in the web results is this:

Not only does this not remotely resemble Coprinus comatus and looks much closer to an inkcap in the Psathyrellaceae family but the image is not even real. The title even says 'Coprinus comatus on transparent background | Premium AI-generated PSD'
The website hosting it is a free stock image site - which is not a reliable source of information for anything much less mushrooms. This is not the first time I have seen google's algorithm scrape stock content for the snippets nor the first time it has been totally wrong. I have reported dozens of images in the snippets over the last year just in the course of casual browsing.
It is however the first time I've seen them use a clearly AI generated image.
404 Media quoted MycoMutant at length on the dangerous knock-on effects of AI imagery polluting search results:
“Google using incorrect images in the snippets I think compounds this issue because it would be logical for a bot to trust a result that is featured so prominently by what should be a trustworthy source,” they said. “Subsequently I have to assume that incorrect images in the snippets are going to have a cascading effect on the accuracy, or rather lack of it in AI identification algorithms. More than once I have since [sic] people try to use bots to scrape data to compile a database for mushroom species and the results have been horrifically inaccurate and potentially filled with dangerously wrong information.”
Speaking to a recurring theme here in the Weird and on the podcast, Emanuel Maiberg of 404 Media puts it powerfully and succinctly:
Google serving an AI-generated image of a mushroom as if it was a real species is highlighting two problem with AI-generated content we’ve covered previously: Potentially wrong and dangerous information being presented as fact, and Google search inability to sort through all the AI-generated content that has flooded the internet and tell users what is real and what isn’t.
It’s not just search results. Foraging books created with generative AI are being sold by Amazon and other retailers, something that can “literally mean life or death” according to the New York Mycological Society.
Rebecca Lexa, a naturalist on Tumblr, has written a handy guide to spotting fake nature books that might get you killed. She also makes a very good point:
I feel really bad for any actual authors who released their books in the past few months. They're likely getting drowned out by this AI junk…
Stepping into a Public Service Announcement mode for a brief moment, I’ll also share her closing paragraph:
Finally, PLEASE reblog this! It's really, really important that people know what to look for, and the more posts we have floating around with this info, the less likely it is someone's going to get poisoned by following what these books have to say.
Elan Trybuch, the secretary of the New York Mycological Society, hammers home the question of AI sawing at the already-thin thread that connects humans to some semblance of reality:
"The problem is, many of these photos look 'close enough' to the real deal. While this can have devastating consequences, I think for the most part it’s just going to add confusion as to: What is real?"
Good question. What is real?
Maybe we shouldn’t have too-fixed a concept of what is ‘real’, but when it comes to mushrooms, I’ll take mine with a grain of salt and the imprimatur of a trusted naturalist, thank you very much.
Australia Poops On Speech
Let’s head Down Under now for a glimpse at the forthcoming Communications Legislation Amendment (Combatting Misinformation and Disinformation) Bill 2024, which John Storey, the Director of Law and Policy at Australia’s Institute of Public Affairs, has called "the single biggest attack on freedom of speech in Australia’s peacetime history."
Among its provisions, the bill threatens to “fine internet platforms up to 5% of their global revenue for failing to prevent the spread of misinformation online,” as per Reuters.
Michelle Rowland MP, the Albanese government’s Minister for Communications, explained the bill’s genesis and limits during the Second Reading on 12 September:
In January 2023, the Albanese government committed to providing the Australian Communications and Media Authority (ACMA) with new powers to create transparency and accountability around the efforts of digital platforms to combat mis- and disinformation on their services, while balancing the freedom of expression that is so fundamental to our democracy.
[…]
To protect freedom of speech, the bill sets a high threshold for the type of mis- and disinformation that digital platforms must combat on their services—that is, it must be reasonably verifiable as false, misleading or deceptive and reasonably likely to cause or contribute to serious harm.
The harm must have significant and far-reaching consequences for Australian society, or severe consequences for an individual in Australia.
The types of serious harms in the bill are:
harm to the operation or integrity of an electoral or referendum process in Australia
harm to public health in Australia including to the efficacy of preventive health measures
vilification of a group in Australian society on the grounds of race, religion, sex, sexual orientation, gender identity, intersex status, disability, nationality or national or ethnic origin, or an individual because of a belief that the individual is a member of such a group
intentionally inflicted physical injury to an individual in Australia
imminent damage to critical infrastructure or disruption of emergency services in Australia, and
imminent harm to the Australian economy.
Critics have pointed out that terms used in the bill, such as ‘serious harm’ and ‘misinformation,’ have definitions which are broad and vague or even non-existent, leaving enforcement open to abuse and interpretation. The result is a law that would “potentially capture any difference of opinion” and “create legal powers for politically biased fact-checkers to determine what is true and false.”
For example, the line item about “the efficacy of preventive health measures” will probably bring out in a cold sweat citizens who lived through “the longest [lockdown] in the world”, during which anti-lockdown protestors suffered “unlawful and unjustified violence” and “unnecessary and unwarranted force” at the hands of the police, followed by charges that required a three-year legal battle to dismiss.
The bill grants the ACMA regulatory and enforcement powers over digital platforms serving Australia:
Under the bill, the ACMA would have the power to approve codes and make standards to compel digital platform service providers to prevent and respond to mis- and disinformation.
A code or standard could include obligations to cover matters such as reporting tools, links to authoritative information, support for fact checking and demonetisation of disinformation.
Approved codes and standards will be legislative instruments subject to parliamentary scrutiny and disallowance.
These powers could be used in the event that the ACMA determines that existing industry efforts to combat mis- and disinformation on digital platform services do not provide adequate protection for the Australian community.
In the event industry efforts to develop or implement an approved code have not been effective, or in urgent and exceptional circumstances, the ACMA would have the power to make an enforceable standard.
Submissions to the government during their consultation period were not all coming from an oppositional perspective. These respondents felt the bill wasn’t restrictive enough, and even asked that “[t]he definition of ‘good faith’ be tightened to include satire and parody as content that has the potential to harm.” That same respondent, Daniel Angus, a Professor of Digital Communications, also lauded the bill taking on ‘inauthentic behaviour,’ in which “problematic activity is less about the truthfulness of the individual content, rather that it is part of a collective action to artificially amplify the reach of the content.”
So if a collective action ‘artificially’ amplifies content, perhaps through some sort of re-posting campaign or marketing push, “the truthfulness of the individual content” doesn’t matter?
Elon Musk, the Howard Stern of billionaires, posted about the Australian bill on X with a single word: “Fascists”.
The sarcastic and not entirely cogent response to Musk’s pithy critique, from Australian Government Services Minister Bill Shorten, has to be the best thing to come out of this entire sordid kerfuffle:
Elon Musk's had more positions on free speech than the Kama Sutra.
Let that sink in.1
As per John Storey, quoted by Sky News Australia:
“The big tech companies will become the censorship and enforcement arm of the federal government to shut down debate and speech that it disagrees with,” the IPA’s Director of Law and Policy said.
“Under these laws even the truth will be no defence. If a citizen were to disseminate information which was factually true, but ACMA or a fact checker labelled it ‘misleading’ or ‘deceptive’ because it ‘lacked context’, then that information would fall within the scope of these laws."
According to Daniel Angus, the professor who wants a crackdown on “inauthentic behaviour”, that kind of reporting should be bannable:
The bill maintains a distinction between misinformation, which is spread by accident, and disinformation, which is spread deliberately.
As my colleagues and I argued in our submission to the government’s draft legislation last year, this distinction isn’t helpful or necessary. That’s because intent is very hard to prove – especially as content gets reshared on digital platforms. Regardless of whether a piece of false, misleading or deceptive content is spread deliberately or not, the result is usually the same.
The bill also won’t cover mainstream media. This is a problem because some mainstream media outlets such as Sky News are prominent contributors to the spread of misinformation.
So Sky News are against the bill, and are accused by fans of the bill of being spreaders of misinformation themselves, which of course would make them subject to enforcement under the bill if their category of speech gets included, which in turn would naturally make them oppositional to it, but their opposition is taken as further proof of their malfeasance, and on and on it goes.
This whole fight over misinformation, and the mental gymnastics necessary to take it at face value, brings to mind the opening lyrics of Noel Harrison’s famous song The Windmills Of Your Mind:
Round like a circle in a spiral, like a wheel within a wheel
Never ending or beginning on an ever-spinning reel
I give the Aussies three-out-of-five poops for this one. 💩💩💩
Hong Kong Poops On Academic Freedom
I had a final lunch on campus with my colleagues.... [W]e were talking about what we’d like to do the most next, and everyone had the same answer: We would like to write fiction because we cannot write the truth on paper anymore.
The above quote is the opening of a new Human Rights Watch report on academic freedom in Hong Kong called “We Can’t Write The Truth Anymore”.
These are the introductory paragraphs:
Following months of massive pro-democracy protests in 2019, the Chinese government on June 30, 2020, imposed the National Security Law on Hong Kong. The draconian law contains overly broad and vague provisions that severely punish peaceful speech and activities, create secret security agencies, give sweeping new powers to the police, impose restraints on civil society and the media, deny fair trial rights, and weaken judicial oversight.
The Chinese and Hong Kong governments moved swiftly to transform Hong Kong from a free society into an authoritarian one. Hong Kong authorities arrested many of the city’s pro-democracy leaders, activists, and protesters, and forced independent media, labor unions, and civil society organizations to close. They reshaped multiple sectors and institutions so they become compliant to the Chinese government.
First up, the most insidious form of censorship:
Most students and faculty interviewed said they self-censor regularly on any Hong Kong and Chinese socio-political topics to avoid trouble. They do this, for example, when expressing themselves in the classrooms, when writing and researching academic articles, when applying for grants, and when inviting speakers for academic conferences.
Some academics don’t have to worry as much:
A small number of academics—those who teach physical sciences, those who are well established in their fields, those who are not ethnically Chinese, and those holding passports from major democracies—told us they felt little or no pressure to self-censor.
Besides the reflex to hold one’s tongue in a repressive atmosphere, there are also experiences of “direct censorship”:
One [academic] said that their department administrators repeatedly stopped them from offering courses on topics that the Chinese government considers sensitive, including threatening them that they would not get tenure if they continued to do so. Four academics said the university administrators and academic publishers censored their academic articles; one said his university reported him to the police for an article he wrote.
The issue comes from the top down. Hong Kong’s Chief Executive, who is selected by Beijing, is also “the chancellor of all eight universities with the power of appointing key members of the universities’ governing councils, which can then appoint university leadership and staff.”
Of all the sentences in the report, and perhaps of all the sentences I’ve read recently on the subjects of censorship and free speech, this one jumped out, as a chilling example of how people can confirm on one hand the absence of overt or violent techniques of repression while describing on the other hand a march towards authoritarianism:
While it is not always clear whether academics are penalized for political reasons, there is a clear trend towards “harmonization” of opinion in academia so that it is increasingly consistent with those of the Communist Party.
“Harmonisation of opinion” is a perfect totalitarian phrase. Who would object to harmony? It sounds so nice. Disagreement is uncomfortable, after all. Let’s just have harmony. Also, knock knock, it’s 2am and the men in leather jackets are here to take you to the gulag. So that you can be harmonised.
How are Hong Kong’s academics being taught to sing in harmony?
The government does that by defaming and intimidating in the state-owned media those academics perceived to hold liberal or pro-democracy views—that is, what the Party considers to be anti-China views—and denying or not issuing visas to foreign academics expressing such opinions. Universities then fire, let go, or deny tenure to these academics.
Professor Carsten Holz, who taught in Hong Kong for many years, described it as “an exceedingly executive, managerial system [that] control[s] every aspects of an academic’s career from promotion to annual performance reviews, salary advancement, teaching duties, and sabbatical leave.”
The report is a sobering read, especially when the interviewed academics share the experience of trying to teach a syllabus that has been trimmed of any potentially problematic content, to students who themselves are subject to the same National Security Law and therefore have to watch how they react and engage with what arises in the classroom. These tensions weren’t helped by the newer method of teaching via Zoom, where sessions are recorded, and the creation of a ‘hotline’ for reporting perceived infractions of the National Security Law.
From one academic:
After the NSL hotline [was set up], everyone worries: If I fail a student or give them bad grades because their assignments are not up to standard, will there be any consequences [for me]? In the past, students can use normal procedures, like appealing their grades or leave us bad teaching evaluations, but after the hotline everyone thinks: If I fail a student, would they report us to the hotline?
Students from the mainland (“mainlanders”) increased worries further, as they were perceived by Hong Kongers as being more likely to report to the authorities.
From a student at Hong Kong University:
In class, to be honest, everyone is cautious around mainland students, though I know in [one class] mainland students would support [human] rights … so that’s a relatively safe space. But if it’s a bigger class, like a hundred or two hundred students, then I wouldn’t discuss these things.… I feel it depends on class size … if there are mainlanders and you don’t know who they are, then we … worry about being reported … plus it depends on the teacher … you need to know where they stand and so you can feel more relaxed in writing.
The unpleasantness is increased by the presence, and tenacity, or media controlled by the Chinese Communist Party. As one academic put it, “The state media plays that role of informal extralegal attack dog.”
In the words of one of the report’s participants:
[The authorities] don’t have to go through the national security bureau to harass you. They don’t need to use the law, but they will use the Party media to name people…. [T]here was a number of editorials that directly criticized several academics by name … involving several universities … and they all left their jobs after a very short time. I knew some of them: They left because it was a very big blow. Because you don’t know whether they will follow it up and act against you.... [This] has created an atmosphere.... If you stay, would you be in trouble? Or this time it was not about me, but would I be next?... If you’re afraid you’d have left, and if you haven’t left then they have erected a barrier in your head [to self-censor] because you don’t want to be next.
No, you certainly don’t want to be next.
I strongly recommend reading the report, and Human Rights Watch’s article announcing its release. It’s an exhaustive look at how a culture of suspicion, fear, snitching, self-censoring, and anti-dissent can take hold in a shockingly short period of time. Students in 2018 and 2019 were posting freely in university spaces on ‘Democracy Walls’, and within five years they’re looking over both shoulders before they say a word.
Horrible.
Hong Kong gets a full five-out-of-five poops. 💩💩💩💩💩
Telegram Spreads ‘Em
Speaking of hand-in-glove relationships between the media and the State, here’s a tale in two headlines from Newsweek:
April 2, 2024: Is Telegram A National Security Threat?
September 24, 2024: Telegram Agrees To Share User Data For Criminal Investigations
Pavel Durov, CEO of the not-encrypted-unless-you-change-a-specific-and-not-clearly-labelled-setting2 messaging app Telegram, has had a Damascene conversion and agreed to act at the behest of and in concert with governments who want users reported to them for enforcement action, or removed from the app for infractions.
From TechStory:
In a statement released on Monday, Durov detailed the updates to Telegram’s terms of service, aimed at combatting criminal activities on the platform. The messaging app, celebrated for its end-to-end encryption and minimal data collection practices, will now cooperate with law enforcement when they present legitimate requests for user information. This marks a departure from Telegram’s previous policy, which largely prioritized user privacy and often dismissed government requests.
As per 404 Media:
“If Telegram receives a valid order from the relevant judicial authorities that confirms you're a suspect in a case involving criminal activities that violate the Telegram Terms of Service, we will perform a legal analysis of the request and may disclose your IP address and phone number to the relevant authorities,” the privacy policy read on Monday.
A day earlier, the policy only specifically mentioned terror cases. “If Telegram receives a court order that confirms you're a terror suspect, we may disclose your IP address and phone number to the relevant authorities. So far, this has never happened,” an archived version of the policy reads.
What could have prompted Durov to change his mind and jump on the surveillance state bandwagon?
From The Hacker News:
The changes have also been driven by the arrest of Durov in France over allegations that the company turned a blind eye to various crimes flourishing unchecked on the platform. He was subsequently released on bail but has been ordered to stay in the country pending ongoing investigation.
Pictured below: Pavel Durov, consigned by French police to the naughty rooftop to think about what he’s done.

As some added background, in 2017, Durov agreed to register Telegram in Russia, but insisted that the app would not share private user data with the Russian government.
As per Reuters:
Pavel Durov, founder of the Telegram messaging app, agreed on Wednesday for his firm to be registered in Russia after coming under pressure from the authorities to do so, but said Telegram would not share confidential user data with anyone.
Durov spoke out after Russia's FSB security service said terrorists had used his app to carry out a deadly suicide bombing on Russian soil and after the communications regulator said it would block Telegram unless it obtained information needed to put the app on an official government list of information distributors.
Once on the list, Telegram would have to store information about its users on Russian servers and hand over user information to the authorities on request.
Durov, writing on social media, said on Wednesday that while he was happy for Telegram to be formally registered in Russia and to supply basic information about the company, he would not do anything to violate the app users' privacy.
"We won't comply with ... laws that are incompatible with Telegram's confidentiality policy or protecting people's private lives," wrote Durov.
Last week, Ukraine banned Telegram for government and military personnel. In the article covering the announcement, The Hacker News mentioned that as of September 21, 2024, “Telegram said it has not provided any personal data to any country, including Russia, and that deleted messages are permanently deleted with no way of recovering them.”
If that’s true3, the French just got access to more Telegram user data than Putin has. Liberté indeed.
That’s it for this week’s Weird, everyone. Thank you as always for reading.
Outro music is Noel Harrison with The Windmills Of Your Mind, a poetic exploration of the ruminative tendency and, to me at least, a fitting description of the way authorities try to justify encroaching into the realms of word and thought for our safety and benefit.
Like a tunnel that you follow to a tunnel of its own
Down a hollow to a cavern where the sun has never shone
Ba dum tss. Those who know, know.
“I’m willing to bet there are thousands, if not millions, of folks who entrust important secrets to Telegram chats in the full confidence that they’re securely protected by default, yet use regular chats with no end-to-end encryption.
What’s especially interesting is that the secret chat button is hidden as deep as possible. It’s not in the chat interface itself. It’s not available at the next level either: even if you tap the name of your chat partner and go to their profile, you won’t find the coveted button there. You need to dig a bit deeper: tap the three dots menu, rummage around in the secondary features, and there it is — the secret chat option with end-to-end encryption.”
BIG ‘if’.
Never being a fan of AI I’m happy to hear of the problems programmers face as I’m certain some of the issues weren’t even thought of during their testing phases. I love the entropy because AI is in nefarious hands. It’s like the old adage in programming…garbage in, garbage out and now an added bonus of an elliptical spin to the system as a whole. The main/only thing that worries me about AI is the growing expertise in faking people, voices, situations, etc. as this is the ultimate tool to framing folks for crimes they never committed or other unfortunate circumstances. That being said, the generation of potentially deadly information by AI is truly awful…wouldn’t wish that on the good people 😎
Hong Kong was such a vibrant place, a unique place. It’s so sad that it’s turned into the hellscape of totalitarianism as the mainland China. Should the cackling word salad “somehow” win the election I envision a rollout of something very similar.